0. OverView
PostgreSQL은 기본적으로 다른 DBMS와 다르게 MVCC를 구현하기 위한 Undo 스페이스가 따로 존재 하지 않고,
데이터가 저장되어있는 블록에 이전 이미지를 저장해 놓고 MVCC를 구현한다.
그래서 Update가 발생하게 되면, 기본 tuple은 플래그를 변경하고, 새로운 Update된 데이터가 새로이 Insert가 된다.
기존 데이터는 Dead tuple로 되고, vacuum이 수행되게 되면 해당 Dead tuple이 있던 부분은 새로이 사용가능한 영역으로 바뀌게 된다. (FSM에서 관리)
그러면 추후 Insert 시에 해당 공간을 사용한다.
그러나 insert, Update가 빈번히 일어나는 테이블일 경우는 vacuum이 돌기 전까지는 dead tuple영역을 사용 할 수가 없게 되므로
테이블 사이즈는 증가 하게 된다. 물론 vacuum이 돌아도 늘어난 테이블 사이즈는 줄어들지 않는다.
Reog를 수행하기 위해서는 Full vacuum을 수행해 줘야 한다.
Full vacuum은 새로운 테이블을 내부적으로 다시 만들고, 데이터를 Insert하는 방식이라고 간단하게 생각하면 된다.
그래서 Insert, Update가 빈번히 발생하는 테이블에서 fillfactor의 중요성을 확인하기 위한 테스트를 진행 함.
테스트는 노트북 VM 환경
Cent7 : 4core / 8G
PostgreSQL : 13.6
Shared buffer : 128 MB
Block size : 8K
autovacuum_naptime : 1min
autovacuum_analyze_scale_factor : 0.1
autovacuum_analyze_threshold : 50
wal_level : replica
max_wal_size : 3G
테스트
기본 fillfactor가 100일때 하나의 블록(8K)에 120개의 tuple이 저장되게 테스트를 진행.
fillfactor를 100, 80, 50, 40, 30으로 변경해 가면서 테스트를 진행 함.
테스트 중에 Autovacuum이 수행 되면 안되므로, 테스트 테이블은 Autovacuum을 OFF 시키고 진행.
하나의 데이터는 insert 한번, Update 세 번 발생하는 로직이다.
주문(order insert) --> 주문확인(check update) --> 배송(delivery update) -> 배송완료(delivery_complite update)
테스트 항목
테이블 사이즈, 인덱스 사이즈, Wal Log 생성 빈도, Hot(%) 등을 테스트
1. 테스트 스크립트
| 데이터베이스 생성 | create database test |
| 테이블/인덱스 | --ff100 create table test_ff100 ( item_code char(10) , order_id char(10) , order_flag char(1) , order_date timestamp , check_flag char(1) , check_date timestamp , delivery_flag char(1) , delivery_date timestamp , delivery_complite_flag char(1) , delivery_complite_date timestamp ) ; alter table test_ff100 set (autovacuum_enabled = false) ; create index test_ff100_idx on test_ff100(item_code) ; --ff80 create table test_ff80 ( item_code char(10) , order_id char(10) , order_flag char(1) , order_date timestamp , check_flag char(1) , check_date timestamp , delivery_flag char(1) , delivery_date timestamp , delivery_complite_flag char(1) , delivery_complite_date timestamp ) with (fillfactor = 80); alter table test_ff80 set (autovacuum_enabled = false) ; create index test_ff80_idx on test_ff80(item_code) ; --ff50 create table test_ff50 ( item_code char(10) , order_id char(10) , order_flag char(1) , order_date timestamp , check_flag char(1) , check_date timestamp , delivery_flag char(1) , delivery_date timestamp , delivery_complite_flag char(1) , delivery_complite_date timestamp ) with (fillfactor = 50); alter table test_ff50 set (autovacuum_enabled = false) ; create index test_ff50_idx on test_ff50(item_code) ; --ff40 create table test_ff40 ( item_code char(10) , order_id char(10) , order_flag char(1) , order_date timestamp , check_flag char(1) , check_date timestamp , delivery_flag char(1) , delivery_date timestamp , delivery_complite_flag char(1) , delivery_complite_date timestamp ) with (fillfactor = 40); alter table test_ff40 set (autovacuum_enabled = false) ; create index test_ff40_idx on test_ff40(item_code) ; --ff30 create table test_ff30 ( item_code char(10) , order_id char(10) , order_flag char(1) , order_date timestamp , check_flag char(1) , check_date timestamp , delivery_flag char(1) , delivery_date timestamp , delivery_complite_flag char(1) , delivery_complite_date timestamp ) with (fillfactor = 30); alter table test_ff30 set (autovacuum_enabled = false) ; create index test_ff30_idx on test_ff30(item_code) ; |
| 데이터 생성/변경 | 테이블 명은 테스트 진행 마다 변경하면서 진행 -- 생성 do $order$ declare i int; begin for i in 1..240000 loop insert into test_ff100 values ( concat('item',lpad(i::bpchar,6,'0')) , 'admin' , 'Y' , now() , NULL , NULL , NULL , NULL , NULL , NULL ) ; end loop; end $order$ ; -- 변경 do $check$ declare i int; begin for i in 1..240000 loop update test_ff100 set check_flag = 'Y' , check_date = now() where item_code = concat('item',lpad(i::bpchar,6,'0'))::bpchar ; end loop; end $check$ ; do $delivery$ declare i int; begin for i in 1..240000 loop update test_ff100 set delivery_flag = 'Y' , delivery_date = now() where item_code = concat('item',lpad(i::bpchar,6,'0'))::bpchar ; end loop; end $delivery$ ; do $deliverycomp$ declare i int; begin for i in 1..240000 loop update test_ff100 set delivery_complite_flag = 'Y' , delivery_complite_date = now() where item_code = concat('item',lpad(i::bpchar,6,'0'))::bpchar ; end loop; end $deliverycomp$ ; |
| 점검 스크립트 | analyze test_ff100 ; select c.relname As tablename , c.relpages As n_page, pg_size_pretty(pg_table_size(c.oid)) As t_size, pg_size_pretty(pg_indexes_size(c.oid)) As i_size, pg_stat_get_live_tuples(c.oid) AS n_live_tup, pg_stat_get_dead_tuples(c.oid) AS n_dead_tup, pg_stat_get_tuples_inserted(c.oid) AS n_tup_ins, pg_stat_get_tuples_updated(c.oid) AS n_tup_upd, pg_stat_get_tuples_hot_updated(c.oid) AS n_tup_hot_upd, pg_stat_get_numscans(c.oid) AS seq_scan, (select (sum(pg_stat_get_numscans(i.indexrelid)))::bigint from pg_index i where c.oid = i.indrelid ) AS idx_scan, pg_stat_get_analyze_count(c.oid) AS analyze_count, c.reloptions from pg_class c where relname = 'test_ff100' ; select pg_ls_waldir() ; \! du -sh /data/pg13.6/pg_wal |
2. 테스트 결과
2.1 요약
auto vacuum을 끄고 수행한 결과 wal count는 크게 차이가 존재 하지 않는다.
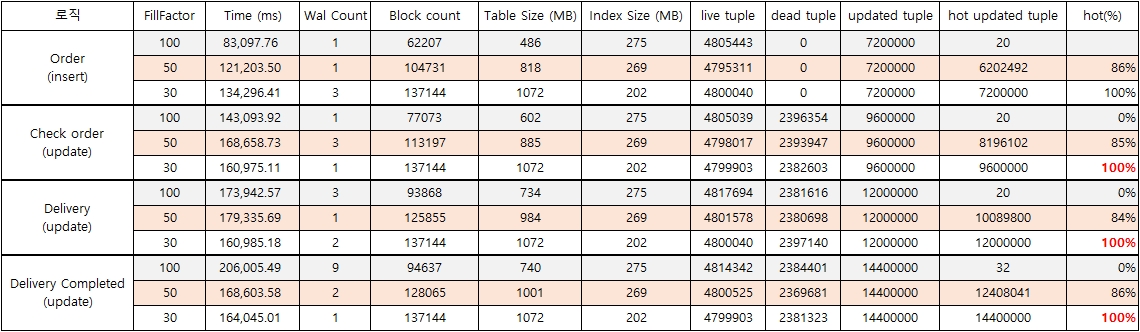
전체 live tuple은 240,000개로 변화가 없고, 테이블 사이즈만 가지고 비교를 하게 되면 fillfactor 50으로 했을 경우가 51M로 가장 적으면서, HOT(%)도 80% 이상을 유지해 준다.
하지만 fillfactor를 30으로 했을 경우 update가 3번 발생해도, tuple이동 없이 기존과 동일한 블록에서 update가 이루어진 것을 확인 할 수 있다 (HOT 100%)
동일 tuple에 update가 3번 발생하여도 50이 30과 비슷한 성능을 유지해 주는 것을 확인할 수 있다.
update 속도도 30이 가장 잘 나오고 있지만, 50도 나름 선방하고 있는 것을 확인할 수 있다.

로직 별 수행 시간 비교

fillfactor별 블럭 개수 비교
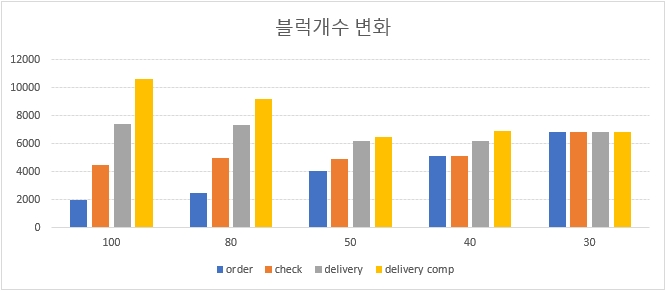
3번의 update를 모두 동일 블럭에서 처리 하는 fillfactor 30은 블럭 개수 변화가 없고, 블럭 개수 변화가 없기 때문에 인덱스 사이즈도 초기와 동일한 사이즈를 유지 하고 있다.
fillfactor별 테이블/인덱스 사이즈 비교

2.2 추가 테스트 (autovacuum 켜고 테스트)
wal 파일 개수 변화가 없어서, 기존에 테스트 시에 사용하던 set (autovacuum_enabled = false) 옵션을 빼고 테스트 진행
데이터는 기존에 240,000 --> 2,400,000로 10배 증가.
fillfactor 100, 50, 30 만 테스트 진행
기본 환경 설정으로 테스트 진행
autovacuum : on
autovacuum_naptime : 1min
autovacuum_analyze_scale_factor : 0.1
autovacuum_analyze_threshold : 50

기본 fillfactor를 이용하여 사용을 하게 되면 테이블 사이즈는 가장 작으나, tuple이동이 많아서 해당 정보를 기록하는 wal file이 많이 생성되는 것을 확인할 수 있다.
fillfactor 30은 초기 데이터가 들어가 있는 순서대로 블록의 데이터가 이동 없이 저장되어 있어서, 인덱스 사이즈가 변화하지 않은 것을 확인할 수 있다.
fillfactor 50은 wal file이 많이 생성되지 않고 update 속도가 fillfactor 30과 비슷한 속도를 내 주므로, 역시 중간적인 위치에 있다.
위의 테이블에 데이터가 있는 상태에서 한번 더 동일 로직을 수행시켜 보자...다시 insert, update, update, update
autovacuum이 잘 동작을 해서인지 f100일때 테이블 사이즈가 다른 옵션일 때 보다 작다.
대신 f30일 경우는 insert된 순서대로 데이터가 저장되어 있어서 인덱스를 이용한 Random I/O가 줄어 들 거라는 정도가 장점이 될 것 같다.
테스트 데이터 셋이 작아서 그런 건지, 테스트가 너무 순차적으로 진행되어서 인가 ?
f100 스크립트로 수행하고, f50 스크립트로 수행하고, f30 스크립트로 수행하고 ~~
Fillfactor를 변경함으로써 얻을 수 있는 드라마틱한 결과가 나오지 않았다.